Innovationgame
Reprinted from TEC 49 Issue 3 (MARCH 2008)
L D HOWE
National Traffic Control Centre (NTCC), 3 Ridgeway, Quinton Business Park, Quinton Parkway, Birmingham, B32 1AF
PACS Numbers: 02.70.Lq, 02.70.Rw, 46.90.+s, 89.40.+k
Key Words: traffic, highway, simulation, modelling
The National Traffic Control Centre (NTCC) collects traffic data in real time. About 1300 locations where traffic flow is reported do not have installed monitoring equipment because, at the design stage, it was not considered cost-effective to build equipment there. These locations use data derived from elsewhere on the network. When NTCC first began to collect and report traffic flow data, the accuracy of the data, particularly the derived data, was erratic and, in some cases, extremely poor. In order to remedy the situation, a major review of the generation of all flow data was commissioned, which led to an analysis of the errors in derived data and the introduction of a set of rules governing the use of TME data for derived data. The Highways Agency has classified the different roads within its jurisdiction as "A", "B" or "C", according to the importance of the routes. The required accuracy for each of the three categories is different. There are several mechanisms that can lead to an increase in the magnitude of the errors in derived data. Each has been considered in turn and assessed using the VEDENS flow simulation. The result of this work was a significant reduction in errors and the accuracy of derived data now meets the required standards.
The Project Network of the Highways Agency (HA) comprises the motorways and trunk roads. Traffic flow information is used for a number of purposes. The HA operates the MIDAS (Motorway Incident Detection and Automatic Signalling) system to warn approaching motorists and help protect the back of queues on motorways. Historical traffic data is used for planning and strategic decision-making. The National Traffic Control Centre (NTCC), run by Serco on behalf of the HA, collects traffic data in real time from over 1,000 MIDAS detectors together with data from over 2,000 of its own Traffic Monitoring Units (TMUs). Collectively, traffic flow monitoring devices, such as MIDAS detectors and TMUs, are described as traffic monitoring equipment (TME).
The HA operates over 13,000 lane-km of main carriageway Lanes and there are over 11,000 Links in the network model used by the National Traffic Control Centre (NTCC). In this case, the term "Link" means a stretch of carriageway where there is no change in the number of lanes or speed limit, no significant change in gradient and neither merge and nor diverge. A typical set of Links that might occur at a grade-separated junction is shown in Figure 1.
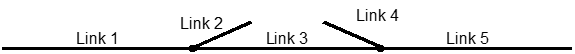
On many Links (e.g. roundabout segments) traffic flow measurement is neither practical nor useful, so NTCC actually reports data on just over 4,000 Links. Each of these Links has been assigned a Reporting Point. In the case of Links with TME, the reporting point is situated at the location of the TME. However, about 1300 LINKS do not have installed TME because, at the design stage, it was not considered cost-effective to build equipment there. These Links use data derived from other Links on the network.
At NTCC, traffic counts are received from each TME for every minute (i.e. the number of vehicles that pass the TME each minute). These are converted to traffic flow rates in vehicles per hour (vph) at every reporting point, in real time, every five minutes (known as 5-minute traffic flows). To accomplish this, the counts for the last ten minutes are added together and multiplied by six. The term "real time" has to be understood in this context. The accuracy of the flow data is assessed as follows:
When NTCC first began to collect and report traffic flow data, the accuracy of the data, particularly the derived data, was erratic and, in some cases, extremely poor. In order to remedy the situation, a major review of the generation of all flow data was commissioned, which led to an analysis of the errors in derived data and the introduction of a set of rules governing the use of TME data for derived data.
The accuracy of loop-based TME is well characterised. It is generally accepted that, for a correctly adjusted TME, the errors for vehicle counts are not greater than 1%. This means that for every Link on the HA Project Network where there is a TME site, the accuracy should be excellent. Although there are several causes of inaccurate data [1], the errors specific to derived data occur even when the TME is correctly configured and adjusted.
Firstly, account must be taken of the distance between the TME and the reporting point, otherwise the traffic data will be reported at the wrong time. For example, if it takes the traffic three minutes to travel from the TME to the reporting point, the traffic flow at the reporting point at a given time must be the traffic flow that occurred at the TME three minutes earlier. This is known as time-shifting the data. However, even using the correct time-shift does not produce an entirely accurate flow rate, because some vehicles travel faster than others. This leads to a smearing of the data, a process known as dispersion. The larger the time-shift, the greater the dispersion, which means that the accuracy of the reported flow rates will be increasingly degraded as the time-shift increases.
Secondly, the data from more than one TME may be combined to calculate the flow at a reporting point using derived data. In the long term, this will be an accurate assessment and is used by NTCC in its application of LIP [1]. However, because the data is received in real time, there will be fluctuations in counts that will result in flow calculation errors. Consider the Link configuration in Figure 2.
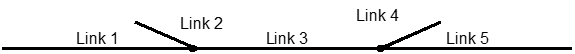
If there were TMEs on both Links 4 and 5, then adding together the traffic counts from those two TMEs and applying the correct time shift would enable one to calculate the flow on Link 3. In this case there will be an additional error, because the error involved in combining the counts from the two TMEs will be greater than the error resulting from a single TME. The normal method used for estimating errors in this situation is give by
Where ErrorT is the total error and Errori is the error of a single TME. In plain language, the total error is the square root of the sum of the squares of the individual errors. So if one error were three and the other error were four, the total error would be five. The total error will always be greater than the largest individual error. This error must be combined with any error resulting from a time-shift in the same way. From this it can be seen that the accuracy of the traffic data will be increasingly degraded as the number of terms increases.
Now consider the case where there is a TME on Link 3 and a TME on Link 1 of Figure 2. The Flow on Link 2 could be calculated by subtracting the counts derived from the TME on Link 1 form the counts derived from the TME on Link 3. If the counts from the TME on Link 2 were 900 and the counts from the TME on Link 3 were 1000, and the error from the time shift and each TME were 1%, the resulting absolute error would be about 17. Now the resultant count (1000 - 900) would be 100, so the error would be 17%. This is an example of error magnification. However, the situation is made considerably worse because there may be occasions where the error results in the calculation of a negative flow. Negative flows cannot be reported, because they would imply traffic travelling in reverse and so are reported as zero. So even in the long term, there will be errors, because averaging the 5- minute traffic flows over time may yield a result that is less than the flows that would be calculated from count data aggregated over the same time.
In the converse case, where there is a TME on Link 3 and a TME on Link 2 of Figure 2, the Flow on Link 1 could be calculated by subtracting the counts derived from the TME on Link 1 form the counts derived from the TME on Link 3. If the counts from the TME on Link 2 were 100 and the counts from the TME on Link 3 were 1000, and the error from the time shift and each TME were 1%, the resulting absolute error would be about 14. Now the resultant count (1000 - 100) would be 900, so the resultant error would be 1.6%. So, it can be seen that when subtraction is used, if the resultant flow is much smaller than the two measured flows, the error in the derived flow will be large, whereas if one of the measured flows is much smaller that the other, the error in the derived flow will be small.
The final case for grade-separated junctions is where there is only a single TME on Link 3. In order to calculate the flows on Links 4 and 5, it would be necessary to estimate what proportion of traffic left the main carriageway via Link 4. Even if the estimate is correct (which can be established by aggregated traffic counting), account must be taken of the specific behaviour of individual vehicles. For example, if the total flow at the TME were 600 vph and the average percentage of vehicles on Link 4 were 10%, then the flow on that Link would be 60 vph, which is 10 vehicles every 10 minutes and the flow on Link 5 would be 540 vph, which is 90 vehicles every 10 minutes. If two additional vehicles chose to leave the main carriageway via Link 4 in any 10-minute period (i.e. 12 vehicles instead of 10) the error for Link 5 would be just over 2%, but the error for Link 4 would be 20%. So the percentage factor used in the calculation greatly influences the accuracy of the calculated flows.
There is one further case to consider: that of the effect of unmonitored minor junctions on trunk roads. In the case of a single, very minor road, such as a farm track or country lane, a simple time-shift may be sufficient. In the case of a net in-flow or out-flow, or where a pair of junctions form a "dog leg" route (see Figure 3) it may be necessary to use a multiplier to estimate the unmonitored traffic on the Project Network.

Where the net in- or out-flow is small, the error magnification will not be large, but if the net cross-flow is significant in the case of a "dog leg", there may be a large increase in the error.
The requirements for accuracy are very specific. The HA has classified the different roads on the Project Network as "A", "B" or "C", according to the importance of the routes. For the three categories the required accuracy is given in Table 1.
Classified flows arise because vehicles are divided into two length classifications: short vehicles less than 6.6m in length and long vehicles greater than 6.6m in length. Because of the difficulty of estimating the length of real vehicles travelling along a road and the differences resulting from small calibration errors, the requirement for classified flows is less stringent than that for traffic flows, which are calculated from the total number of all vehicles. It is a requirement that 95% of all flows satisfy the above criteria.
Although the accuracy requirements appear unremarkable, each of the three categories is assessed by sampling and statistical analysis. To this end, the errors of every flow in each category are treated as belonging to a single, normal distribution. The result is that, in order to satisfy the above criteria, each individual Link requires the flows to have a systematic error of no more than 1% and random errors of no more than about 3%. A single sample with a significant mean error will distort the statistical distribution, causing a failure of the accuracy assessment.
Because the criteria for accuracy require such stringent statistical compliance, it was essential to understand the effect of the various sources of error in derived data and define rules for the specification of formulae to produced derived flows. The only way to be certain of the errors is to measure the true flow at the derived point over a period of time. In practice this is not possible. However, the VEDENS traffic flow simulator [2] presented itself as an ideal tool in this respect because it is possible to calculate flows from remote monitoring sites within the simulation model and compare them with flows from monitoring sites situated at the Reporting Point in question. Using this method, it became possible to determine the magnitude of the error produced by using the various sources of error in derived data, as described in Section 2 above. All calculations were performed using a three-lane unidirectional carriageway model with a speed limit of 70 mph. The mix of vehicles used is given in Table 2.
The vehicle type for each vehicle is chosen at random from the above distribution as it enters the model. There is a random element of plus or minus 10% variation in the vehicle top speed. Each vehicle is allocated a driver, also chosen at random. The mix of driver characteristics used is shown in Table 3.
The driver safety gap is the minimum gap a driver is comfortable to leave between the front of the vehicle being driven and the rear of the one in front. This gap may become smaller under braking conditions or when other vehicles change lane. The safety gap is also related to the willingness of the driver to exceed the speed limit, with aggressive drivers being most willing to drive at high speeds. In all cases, the model was allowed to run for at least one hour (in simulation time) prior to the beginning of the calculations, to allow the flow to settle down along the entire length of the carriageway.
Time-shift calculations were performed using spatial shifts of 200 m, 500 m, 1 km, 2 km, 3 km, 4 km, 5 km, 10 km and 15 km. This was achieved by comparing the upstream flow with the flow at the relevant distance downstream, using a range of different time-shifts for each distance. The calculations were performed using steady flow rates of 600 vph, 1200 vph, 1800 vph, 2400 vph, 3000 vph, 3600 vph and 4200 vph. Two further calculations were performed, one using a cyclic flow where the flow was changed by 100 vph every five minutes, ramping up from 600 vph to 4200 vph and back to 600 vph again, etc. The other used a congested flow, which was achieved by using an entry flow rate of 4200 vph and imposing a lane closure at the end of the model. In the latter case the model was allowed to equilibrate for 4 hours to ensure uniform conditions at all time-shift distances.
For each calculation, time-shifts of the upstream data were combined as 10-minute moving averages. The downstream data were similarly combined as 10-minute moving averages. The downstream averages were subtracted from the upstream averages and the mean of the absolute errors was calculated. The time-shift that gave the smallest mean of the absolute errors for all flow rate calculations at each distance was then selected as the optimum time-shift for that distance.
The results for congested flow were not sensitive to time-shift and the mean absolute errors displayed little variation for all values of time shift. Hence, the optimum value of time-shift chosen is essentially unaffected by the results for congested flow. The optimum time shift was 1 minute per 1.5 km. This is equivalent to a speed of 56 mph, substantially less than the average speed of the vehicles in the model, which was close to the speed limit of 70 mph. The explanation of this phenomenon is that density wave nodes travel along the carriageway at a speed that is governed by the speed of the slowest vehicles. Faster vehicles will catch up with the rear of a node, progress through it at a reduced speed and then leave the front of the node at a higher speed than the node. Thus the appropriate speed limit to use for time shifting should equate to the expected mean speed for HGVs. The Application of this principle for various speed limits and road types is illustrated by Table 4.
In order to reduce the errors to a minimum, a simple interpolation was chosen for the time shifts. This was achieved by calculating the exact time shift and carrying out a linear interpolation between the adjacent one-minute time-shifts. For example, at 70 mph, a distance of 4 km is equivalent to an exact time-shift of 2.67 minutes. The method consists of adding two thirds of the 3-minute time-shifted up-stream flow and one third of the 2-minute time-shifted up-stream flow. The accuracy achieved has been assessed by calculating the standard deviation of the errors. The standard deviations, assuming all flow rates for each distance belong to a single distribution, are shown in Table 5.
In all cases the true mean of the errors was no greater than 0.03%, with most being much smaller. There is 95% confidence that any given error will lie within two standard deviations of the mean. If it assumed that the time-shift error is one third of the total error, the maximum allowable standard deviation and time-shift error can be assessed, as shown in Table 6.
As expected, the impact of adding two flows together to derive the flow on a downstream or upstream Link proved to be low. The effect was equivalent to introducing an additional error with a standard deviation of about 0.8%, which is acceptable for all accuracy requirements. A special form of addition is averaging, where the flows from an upstream TME and a downstream TME are averaged, with the appropriate time-shifts. In all cases, the standard deviations of the errors were similar to those of the longest time-shift used, so the averaging process did not introduce any significant additional errors over and above the time-shift errors.
The subtraction errors produced results divided into two classes, again as expected. Where the two measured flows were large, as in calculating a ramp flow from upstream and downstream main carriageway flows, the errors were unacceptable, with standard deviations typically about 13% where the ramp flow was about 10% of the main carriageway flow. On the other hand, where one of the measured flows is a ramp and the other is a main carriageway, the errors were acceptable, with standard deviations typically about 1.3% where the ramp flow was about 10% of the main carriageway flow. This would be acceptable for all accuracy requirements. Where the accuracy requirement is less demanding, ramp flows of up to 30% may be acceptable.
Like subtraction, multiplication errors produced results divided into two classes, again as expected. Where the fraction was very different to unity, as in calculating a ramp flow from upstream or downstream main carriageway flows, the errors were unacceptable, with standard deviations typically about 15% where the factor was 0.2. On the other hand, where the fraction was close to unity, the errors were acceptable, with standard deviations typically about 2.3% where the factor was about 1.2. This would be acceptable where the accuracy requirement is 15%. Where the accuracy requirement is different, different factors are acceptable.
Where multiple TME are used, the standard deviation associated with each TME or mathematical operation should be incorporated in the total. The square root of the sum of the squares of each standard deviation should be used for this purpose. Thus, it can be seen that if four TME are used and each is associated with a standard deviation of 1.0%, the result would be an overall standard deviation of about 2.0%. In addition, the compounded error resulting from using multiple TME should be combined with other errors, such as time-shift and calculation errors. For the purposes of counting TME, where there is an average calculation, as described in the previous section, it should be regarded as single TME. This is because the calculation of an average results in a similar standard deviation to that for a single time-shift.
The VEDENS traffic flow simulator has been used to make specific recommendations for the calculation of derived traffic flows. The specific recommendations are shown in Table 7.
The implementation of the recommendations has resulted in a significant reduction in the errors caused by deriving data from remote monitoring equipment. The derived data used by NTCC currently meets the required standards for accuracy. The recommendations of Table 7 can be recommended as a sound basis for assessing whether it is possible to use derived data or whether additional monitoring equipment should be commissioned.
[1] L D Howe Detecting Errors in Loop-Based Flow Data Using a Long-term Integration Process (LIP) TEC 48 Issue 7 (July 2006)
[2] L D Howe Studies of Traffic Flow Phenomena Using the VEDENS Computer Code Physica A 246 (1997)

 Download a PDF version of this paper
Download a PDF version of this paper